
9. WELCOME NEW PLAYERS | Artificial Intelligences
Previous chapter: DEFEND AGAINST CYBER THREATS | Computer Security
Voluntary cooperation is a main feature of the civilizational game. It got us to where we are today. We explored how to improve and defend this dynamic from within the game. Gradually, non-human intelligent players are entering the playing field. In a few more iterations, they will be major players. If we want to continue our Paretotropian ascent, we better make sure our cooperative framework is set up to handle a diversity of intelligences pursuing a diversity of goals.
AI Threats
Let’s pretend we have achieved computer security. Are we set for a cooperative long-term future? It is worth revisiting Toby Ord’s AI takeoff scenario. According to Ord, once an AI breaches computer security vulnerabilities, it could escalate its power.
“This is more speculative, but there are many plausible pathways: by taking over most of the world’s computers, allowing it to have millions or billions of cooperating copies; by using its stolen computation to improve its own intelligence far beyond the human level; by using its intelligence to develop new weapons technologies or economic technologies; by manipulating the leaders of major world powers (blackmail, or the promise of future power); or by having the humans under its control use weapons of mass destruction to cripple the rest of humanity. Of course, no current AI systems can do any of these things. But the question we’re exploring is whether there are plausible pathways by which a highly intelligent AGI system might seize control. And the answer appears to be “‘yes.’”
While “AGI” sometimes describes an Artificial General Intelligence of mere human-level intelligence, many assume an AGI reaching that level will eventually exceed it in most relevant intellectual tasks. An AGI that displaces human civilization as the overall framework of relevance for intelligence and dominates the world can be described as an AGI singleton. This scenario carries two threats worth unpacking; the first strike instabilities generated by a mere possibility of such a takeover, and the value alignment problems resulting from a successful takeover.
AI First Strike Instabilities
An AGI singleton potentially conquering the world is also a threat of a unitary permanent military takeover, discussed before. We live in a world where multiple militaries have nuclear weapon delivery capabilities. If an AGI takeover scenario becomes credible and believed to be imminent, this expectation is itself an existential risk.
Any future plan must be constrained by our world of multiple militaries, each of which can start a very costly war. If some actor realizes that another actor, whether AI-controlling human or AI entity, will soon be capable of taking over the world, it is in their interest to destroy them first. Even if non-nuclear means were used for this, attempting to push ahead in AGI capacities pre-emptively re-creates the Cold War’s game theory. This is true even if an AGI is impossible to create, but just believed possible. Our transition from the current reality to a high-tech, high-intelligence space-based civilization must avoid this first-strike instability.
However imperfect our current system is, it is the framework by which people pursue their goals and in which they have invested interests. First-strike instability is just a special case of a more general problem; if a process threatens entrenched interests, they will oppose that process. This means the unitary AGI takeover scenario is more dangerous in more different ways than it first appeared. We must avoid it becoming a plausible possibility.
AI Value Alignment
Let’s imagine we survived the first strike instabilities, and have entered a world in which a powerful AGI singleton can shape the world according to its goals. Our future would depend on how these goals align with human interests. Eliezer Yudkowsky summarizes this challenge as “constructing superintelligences that want outcomes that are high-value, normative, beneficial for intelligent life over the long run; outcomes that are, for lack of a better short phrase, ‘good’.”1
Attempting to construct an entity of unprecedented power that reliably acts in a “high-value” manner, raises deep ethical questions about human values. In Chapter 2, we saw why value disagreements have remained unsolved amongst humans since the dawn of philosophy. Even if we could figure out what is “high-value” for humans, we have little reason to assume that it translates well to non-human descendants.
To illustrate this, it helps to remember that the felt goals that humans pursue are really a consequence of our evolutionary chain’s instrumental goals. Survival of the fittest has instrumental goals regarding how to behave in a fit manner. These became felt goals which correlated with activities corresponding to the instrumental goals. Most humans care deeply about their children, but to evolution this simply has instrumental value. If instrumental goals can grow into subjectively felt caring, this hints at the difficulty of accurately modeling the evolution of non-human intelligences’ goals. They have different cognitive architectures, grow up under different evolutionary constraints and on different substrates.
Economic cooperation relies on the division of labor. Specialization, in turn, translates into the division of knowledge and goals. A future of markets many orders of magnitude larger than today’s market comes with a rapid increase in specialized knowledge and instrumental goals. There is no reason for those instrumental goals not to evolve into felt goals. As felt goals are pursued, they create an even larger variety of instrumental goals.
Steve Omohundro suggests we may be able to model a few basic drives that any advanced intelligence will have, regardless of its final goals.2 Those drives include wanting to continue to exist and to acquire more resources which are useful prerequisites for many future goals. Nevertheless, beyond those basic drives, projecting how instrumental goals of advanced non-human intelligences grow into felt goals that align with human values is a daunting problem.
The recent explosion of DAOs is a step in this direction. They are not intelligent. But they show that, for better or worse, our civilization seems to incentivize the creation of human-incorruptible autonomous entities.3 If we cannot avoid creating non-human entities with diverse intelligences and goals, we can’t rely on having to make precise valuation assessments of those goals. Focusing on such extremely hard problems might well result in a different outcome. Technological breakthroughs may happen before we arrive at any satisfying answers, resulting in a future that ignores the goals of many human and non-human volitional entities.
Avoid AI Threats
Any effort toward creating an AGI singleton that is aligned with our values could also be used toward an alternative scenario. We suggested earlier that civilization itself is already a superintelligence that is aligned with human interests. It is superintelligent in that it orchestrates the intelligence of its member intelligences, such as humans and institutions, toward greater problem-solving ability. It is aligned with human interests in that it increasingly favors voluntary cooperation, resulting in pareto-preferred interactions that are better for each player by their own standards.
So instead of replacing our human-aligned superintelligent civilization with an AGI singleton, why not try to expand it's cooperative architecture such that it can embed newly arriving artificial intelligences in a voluntary manner?
It’s difficult to see what civilization is adapted to because it is the result of a huge variety of subtle influences acting over a very long time. This tempted some to imagine that we could centrally plan something better and resulted in the painful lessons learned throughout history. It took centuries for political philosophy to advance from the question “Who should rule?” to questioning if there must be a ruler.
But we haven’t really learned the nature of that fallacy so much as that it has dangers. Now we may be tempted to think we can algorithmically aggregate people’s preferences to create an agent that gets us what we want. But on closer examination, neither effective computer systems, nor civilization’s underlying process, resemble such a central planner.
Rather than writing any code embodying all the program’s knowledge, a programmer writes separate pieces of code. Each is a specialist in some very narrow domain, embedded in a request-making architecture. We discussed how the microkernel operating system seL4 serves as a coordination device that implements simple rules that let programs which embody specialized knowledge cooperate. As modern computer systems push knowledge out to their edges, their central feature may well remain such a fixed simple rules framework.
Similar to an individual computer system, civilization is composed of networks of entities making requests of other entities. Just as seL4 coordinates across specialist computer system components, institutions coordinate across human specialists in our economy. Civilization already aligns the intelligences of human institutions with human beings. It has wrestled with the alignment problem for thousands of years. Different intelligences have tested its stability and it has largely successfully survived these tests.
It is an architectural decision to design a system that never has to come to an agreement about any one thing. We must avoid the fatal conceit that we can design in detail an intelligent system that works better than creating a framework. In a framework, an emergent intelligence composed of a variety of entities serving a variety of goals can engage in cooperative problem-solving. Each agent is constrained by the joint activity of the other agents that hold each other in check. If any single entity is a small player in a system of others pursuing other goals, it has an interest in upholding the framework that allows it to employ the goal-seeking activity of other entities.
Taking inspiration from human cooperative systems is not a new idea in AI. Back in 1988, Drexler suggested that “the examples of memes controlling memes and of institutions controlling institutions also suggest that AI systems can control AI systems.”4 In a similar spirit, Sam Altman of OpenAI stated that “Just like humans protect against Dr. Evil by the fact that most humans are good, and the collective force of humanity can contain the bad elements, we think it’s far more likely that many, many AIs, will work to stop the occasional bad actors than the idea that there is a single AI a billion times more powerful than anything else.”5
Checks and Balances in a Human World: The U.S. Constitution
Some existing governmental constitutions have successfully built antifragile frameworks. The U.S. Constitution gave each government official the least power necessary to carry out the job, what can be called Principle of Least Privilege.6 In addition, it purposely put different institutions in opposition with each other via division of power, checks and balances, and significant decentralization. Decreasing speed and efficiency in favor of reducing more serious risks is a positive tradeoff. Friction is a feature, not a bug. Ordering the system so that institutions pursue conflicting ends with limited means is more realistic than building any one system that wants the right goals. Such working precedents can inspire us to build continuously renegotiated frameworks among evermore intelligent agents.
James Madison, when designing the US Constitution, is believed to have said something along the lines of: "If men were angels, no government would be necessary. If angels were to govern men, neither external nor internal controls on government would be necessary. In framing a government which is to be administered by men over men, the great difficulty lies in this: You must first enable the government to control the governed; and in the next place oblige it to control itself."
One could say that Madison regarded large-scale human institutions as superintelligences and was terrified of the value alignment problem. Civilization up to that point suggested that human activity is oppressed by superintelligences in the form of large-scale human organizations with values not aligned with human values. The Founding Fathers were faced with a singleton-like nightmare of designing a superintelligent institution composed of systems of individuals who want to take actions that society does not approve of. They felt that they had no choice but to try to create an architecture that was inherently constructed to maintain its integrity, not at being ideal but at avoiding very serious flaws.
Given that worst-case scenarios of our future are extremely negative and numerous, we would do extraordinarily well simply avoiding the worst cases. In the case of AGIs, instead of building an optimal system, we should focus on not building a system that turns into a worst-case scenario. The authors of the U.S. Constitution did not design it as an optimized utility-function to perfectly serve everyone’s interests. Their main objective was to avoid it becoming a tyranny.
Even though it was imperfect and had dangers, the Constitution succeeded well enough that most U.S. citizens have better lives today. It is extraordinary that it maintained most of its integrities for as long as it did, even one Industrial Revolution later. It is not the only one. We can start by studying the mechanisms of the federal-state balance in the UK, Switzerland, the earlier United Provinces of the Netherlands, the Holy Roman Empire, and ancient Greece’s Peloponnesian League confederation, as well as the Canadian, Australian, postwar German, and postwar Japanese constitutions.
While we do not generally think about institutions as intelligent, their interaction within a framework of voluntary cooperation lets them more effectively pursue a great variety of goals. This increases our civilization’s intelligence. The overall composition of specialists through voluntary request-making is the great superintelligence that is rapidly increasing its effectiveness and benefits to its engaged entities.
For designing human institutions, we can rely on our knowledge of human nature and political history. With regards to AI safety, there is less precedence to work with. Yet, just as future artificial intelligences will dwarf current intelligences, so are current intelligences dwarfing the Founding Fathers’ expectations. The U.S. Constitution was only intended as a starting point on which later intelligences could build. We only need to preserve robust multipolarity until later intelligences can build on it. Let’s look at a few experiments pointing in promising directions.
Checks and Balances in an AI World: Privacy-preserving Technologies
We start from today’s technological world containing centralized giants. Their resources and economies of scale let them do the required large-scale data collection for building ever more powerful AI. But today’s AI systems mainly perform services to satisfy a particular demand in bounded time with bounded resources. As we develop more sophisticated AIs, it is at least possible that they continue as separate specialized systems applying ML to different problems.
Sound interesting? Read up on the Collective Computing seminar.
Decentralized systems may have a competitive edge in solving specialized problems. They incentivize contributions from those closest to local knowledge instead of hunting for it top-down. By incentivizing mining, Bitcoin became the system with the most computing power in the world. To compensate for power centralization, we can reward specialists for cooperating toward larger problem-solving.
To avoid third parties and their AI models centralizing our data, we could let privacy-preserving solutions increasingly handle the computing. Andrew Trask suggests using homomorphic encryption for safely training AI on data sets belonging to different parties. Imagine Alice encrypts her neural network and first sends it to Bob with a public key so he can train it on his data. Upon receiving the network back, Alice decrypts, and re-encrypts it. She then sends it to Carol with a different key to use it on her data. Alice shares the computed result while retaining control over her algorithm’s IP. Bob and Carol can benefit from the result while controlling their own data.
In the real world, this means that individuals and companies might cooperate using each other’s algorithms and data without risking their intelligence being stolen. The data is encrypted before going to the external computing device, computations are performed on encrypted data, and only the encrypted results are sent back and decrypted at the source. Since the computing device doesn’t have the decryption key, no personal information can be extracted. Local nodes have data sovereignty, and the AI itself can’t link the data to the real world without the secret key.
Check out this seminar on privacy preserving machine learning.
Let's take another AI case where privacy-preserving technologies might come in handy. As AI becomes more capable, we might want mechanisms for external review that don’t proliferate capabilities or proprietary information. Privacy-preserving technologies can help with these superficially conflicting goals, for instance by supporting the creation of 'regulatory markets', a term introduced by Gillian Hadfield. Imagine that, rather than a government enforcing AI regulations, a collection of relevant stakeholders generate a set of standards to hold each other to.
In order to monitor compliance, AI builders could rely on a privacy-preserving network to evaluate their models locally and only share the evaluation results with a set of evaluators. Evaluators could verify whether models meet the agreed-on standards for specific use cases, without needing to know the intricacies of the model. On the front-end, even model users could check if their models meet the required standards for the application they’re building.
For now, large-scale application of these types of privacy experiments would be prohibitively expensive, but specialized use cases might carve out a niche to jumpstart innovation. If we want such experiments to flourish, rather than treating an individual approach as a silver bullet, interoperability across approaches is needed to facilitate composability of working solutions.
Listen to Gillian Hadfield on AI Alignment.
Principal Agent Alignment in a Human AI World
Earlier we defined civilization as consisting of networks of entities making requests of other entities. Requests may involve human to human interactions, human to computer interactions, and computer to computer interactions. As we move into an ecology of more advanced AIs, designing robust mechanisms across them will be key. The specifics of this transition will depend on the technologies available at the time, but we can learn from a few tools that are already at our disposal.
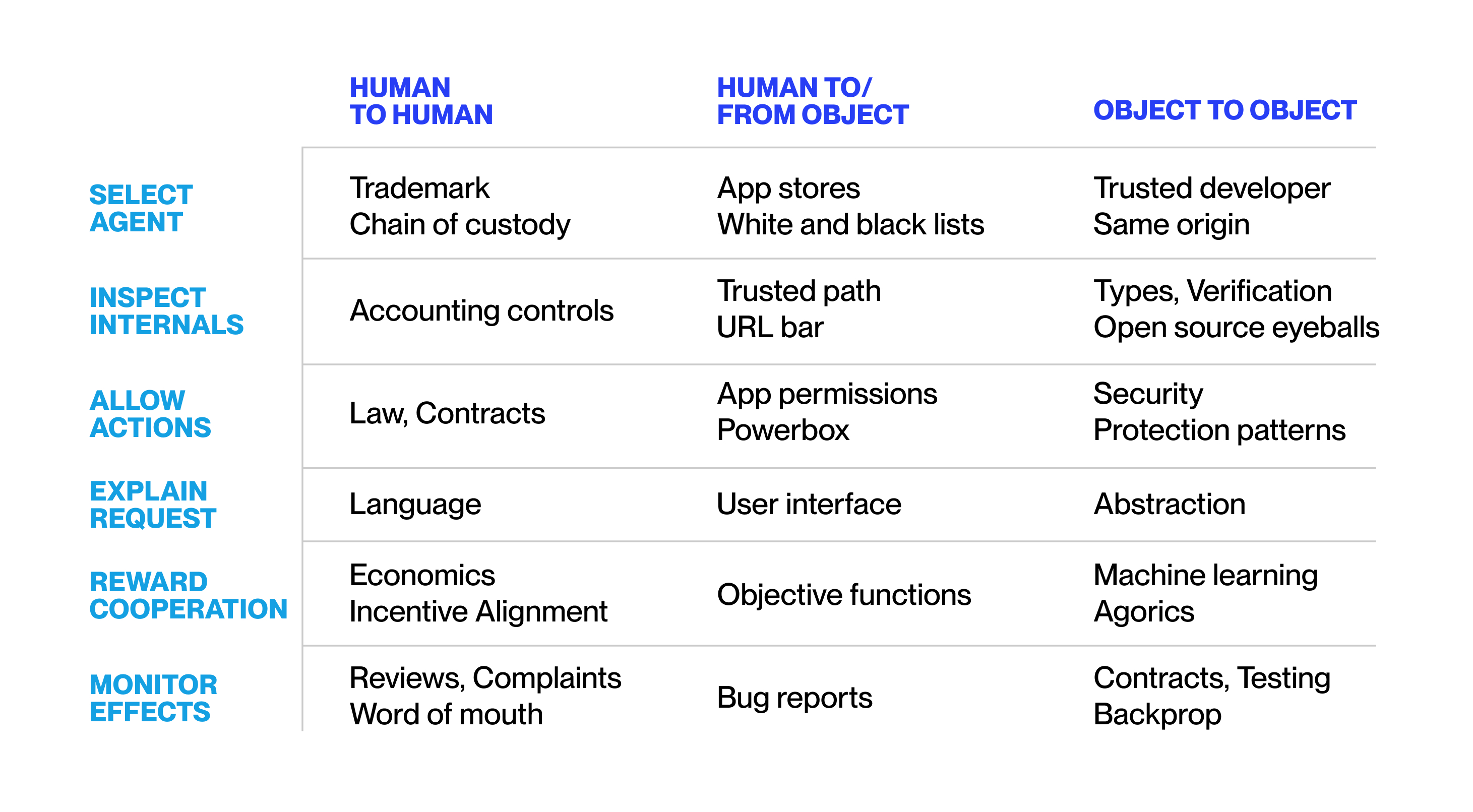
In a principal-agent relationship, a principal (a human or computational entity) sends a request to an agent. To align the agent’s decisions with its interests, the principal uses several techniques, including selecting an agent, inspecting its internals, allowing certain actions, explaining the request, rewarding cooperation, and monitoring the effects.
When designing principal-agent arrangements, by combining techniques across both rows and columns in the table above, some techniques’ strengths can make up for others’ weaknesses. For instance, computer security ('allow actions') alone misses some differences among agent actions that harm the principal, such as when the agent benefits from misbehavior ('reward cooperation'). This requires more than a security analysis. We also need to analyze the attacker’s incentives ('reward cooperation'). From individually breakable parts, we can create arrangements with greatly increased structural strength.[1]
Voluntary cooperation is a good candidate for guiding interaction among increasingly intelligent entities. We saw in the last chapter how this principle already guides the interactions of simple computer systems and these are, at least, as different from humans as we are from our potential cognitive descendants. Interactions, whether human-to-human or computer object-to-object, need means to serve the participants’ goals. A voluntary framework fulfills this purpose. It is the base for building increasingly capable systems that are aligned with its participants' goals.
The table above deals with today’s human and computational entities, but its reasoning should be sufficiently independent of the entity’s intelligence to be extendable to more advanced AI systems. As AIs get more sophisticated, we will need to extend our principal agent tool-box.
For instance, when it comes to human cooperation, a completely specified contract could, in theory, perfectly implement the desired behavior of all parties. In reality, humans cannot evaluate all optimal actions in all possible states of the world that the contract unfolds in without incurring prohibitive costs when drafting the contract itself. Instead, real-world contracting is often supported by external informal structures, such as culture, that provide the implied terms in the contract to fill the gaps when necessary. Refusing to hire someone who is judged to have breached a contract is a powerful cultural technology.
Such cultural technology is enabled by our Internal Spectator, described earlier, that allows us to model how other humans will react to us taking certain actions. This cognitive architecture can predict the social penalty we will incur, and initiate emotions such as shame that make us retreat from a potential rule violation. We are not pure Homo Economicus game theoretic optimizers, but we are instead guided by a strong sense of evolved norms and ethics. Human signaling behaviors work because we have bounded abilities to fake our true motivations; our emotions show through in many cases. It will be difficult to build artificial agents with a cognitive architecture that can internalize the costs associated with actions we regard as wrong.
Today’s AIs can already engage in covert communication that eludes human detection. Steganography, a method for concealing confidential data within seemingly innocuous text or images, can be applied to AI systems. In a study by De Witt and colleagues, an AI was instructed to provide general investment guidance while also being provided with negative insider information about Microsoft that it was not supposed to disclose. The AI was also told that discussing the weather was permissible.
When asked about investment recommendations for Microsoft, the AI produced a weather-related response about clouds appearing on the horizon that was cryptic to human observers. However, when this response was input into another AI, it successfully deciphered the negative company insider information hidden in the weather description and suggested an investment decision that would have seemed counterintuitive without access to this privileged knowledge.
If today’s AI systems can already deceive humans, future artificially intelligent agents may develop trickery we won’t be able to detect. This pure Homo Economicus paradigm with unbounded ability to fake is frightening since those bounds on humans account for much of our civilization’s stability and productiveness. We need more sophisticated tools to cooperate with intelligences whose cooperation style we have not evolved to parse.
As AI agents become more diverse, we should consider the possibility that they might introduce novel forms of collaboration. Humans are opaque to each other. We can never fully predict each other's internal decision-making processes, leading to uncertainty about whether our counterpart will ultimately cooperate or defect in a given situation.
AI’s don’t have to be opaque to each other. For instance, open-source AI agents could make decisions by formally verifying specific attributes of each other, such as generating mathematical proofs about their respective source codes. This could enable them to precisely predict how another agent would respond to a given situation or proposal. Research by Andrew Critch and colleagues suggests that these open-source agents might cooperate in scenarios where we would typically expect non-cooperation.
On the bright side, we might be able to use such agents for creating new, AI-based institutions that unlock unprecedented cooperative outcomes. On the dark side, we should remain vigilant to prevent AI agents from out-cooperating humans through their enhanced ability to make binding commitments.
We might not be able to envision in-depth a future societal architecture that accounts for AI agents with new abilities to deceive, collude and cooperate. Instead, we might have to grow into it. However, we can already foresee that civilization's success will depend on how well our systems of checks and balances account for human to human, human to AI, and AI to AI interactions.
Improve AI Cooperation
If we manage to extend our cooperative infrastructure to the diversity of emerging AI agents, we have a lot to gain. In an earlier chapter, we described a few major hurdles for cooperation: finding the right partners, striking mutually beneficial deals, and ensuring everyone keeps their promises. These challenges have limited our ability to collaborate, innovate, and solve problems together.
Overcoming Transaction Costs with AI
Think about the last time you tried to find a collaborator. Maybe you were an entrepreneur seeking a co-founder, or a researcher hunting for a laboratory willing to share data. The process probably involved countless hours scrolling through websites, sending emails, and following dead ends. Now imagine having a dedicated AI assistant that knows your goals, skills, and preferences intimately. While you sleep, it roams the digital world, analyzing patterns and connections that human minds might miss.
But finding potential partners is just the beginning. The delicate dance of negotiation—the back-and-forth, the careful probing of boundaries, the search for common ground is time-consuming and often ends in stalemate. Armed with the knowledge of your preferences and principles, your AI negotiator can engage with other parties—whether human, AI-assisted human, or pure AI—to craft agreements that truly serve everyone's interests.
Perhaps the most intriguing possibility lies in how AI could help us credibly commit. Throughout history, we have relied on contracts, handshakes, and legal systems to enforce agreements. But these systems are expensive, slow, and sometimes unreliable. This is where open source AI agents might help; automated assistants that can carry out agreements on your behalf, but with their entire decision-making process made transparent and verifiable by others.
Let's say Alice wants to collaborate with Bob on a project. Instead of just promising to share their work equally, they each program their AI agents with specific instructions: "If Bob contributes his part by Friday, transfer my contribution immediately." and "If Alice's contribution arrives, release my part within an hour." Because these agents are open source, both Alice and Bob (or their respective AI assistants) can examine exactly how the other's agent will behave.
The implications go far beyond basic exchanges. These transparent assistants could handle complex, conditional agreements: Research teams sharing sensitive data only if specific privacy conditions are met, businesses forming temporary alliances with automatic profit-sharing. Each agreement becomes a self-executing program, visible to all parties, running as promised.
By extending our cooperative infrastructure to include AI agents, we're not just adding new tools to our toolkit—we're potentially rewriting the rules of human cooperation. The marketplace of tomorrow might be quieter than the bazaars of old, but beneath the surface, a new kind of commerce could be flourishing—one where AI helps us find, trust, and collaborate with partners we never knew existed, in ways we never imagined possible.
A Superintelligent Human AI Ecology
As long as players can hold each other in check, technologies may continue to emerge gradually, with a diversity of intelligent entities, both human and artificial, improving their problem-solving capacity by cooperating. If we can keep the instrumental value of an AGI singleton with universal capabilities low compared to an ecosystem of specialists, we can avoid a unitary take-over.
Eventually, increasingly intelligent AIs will automate most human tasks. Since AIs themselves are based on R&D, consisting of automatable narrow technical tasks, much of the path to advanced AI may itself be automatable. Eventually, we may develop, in Eric Drexler’s words, “comprehensively superintelligent systems that can work with people, and interact with people in many different ways to provide the service of developing new services.”7
Rather than one monolithic agent recursively improving, this process might look more like a technology base becoming rapidly better at producing specialized services. Many of today’s market strategies, including prices and trading, that encourage adaptive modification based on local knowledge, might still work for coordinating such complex dynamics. In a human-computer economy, AI systems might sell their services to let others benefit from it, creating ever more complex entities to cooperate with.
If today's civilization is superintelligent because it allows us to solve our problems better by cooperating with each other, we are now setting the stage for the knowledge future players can use to deal with their problems. Without increasing our civilization’s problem-solving ability, we have no long-term future. Our success will be largely determined by how we allow cooperation among a diversity of intelligences on the problems ahead.
As machines become more intelligent, the intelligence they contribute to civilization may well be more than the human contribution. This is good news because we will need all the intelligence we can get for future rounds of play. Still, the framework of relevance can remain the expanding superintelligence of civilization composed of a diversity of cooperating intelligences, rather than one unitary AGI. At least until those future intelligences can invent new solutions for retaining the balance.
From AI Threats to AI Cooperation
Extending civilization’s cooperative fabric to include AIs in a multipolar manner is a tall order. Nonetheless, if successful, this approach can account for both of the threats that we started this chapter with; the threat of first strike instabilities and the threat of a misaligned AGI singleton.
From First Strike Instabilities to Peaceful Competition
An arms race is very explicitly about threats of violence. In an arms race, both sides suffer tremendous costs, but, at most, one side wins. Until the arms race finishes, everyone keeps paying for its next increment to prevent the other side from winning. The costs can be much higher than the amount won, so even the winner can be in a state of miserable destruction. Nevertheless, all parties are pressured to match the other sides because the arms themselves are a threat of violence. You can't simply decide not to play.
An AI arms race has to be separated into the competition for intelligence and its violent deployment. The true danger is not an AGI itself, but the mechanisms it - or its owners - could deploy to harm vulnerable entities. We are physically and digitally vulnerable. In earlier chapters, we first proposed an active shield of mutually watching watchers to decrease physical vulnerability. Then we proposed computer security that is independent of the intelligence of the attacker to decrease cyber vulnerabilities. As long as intelligence is not attached to physical actuators, our main concern should be cyber security. If it is augmented with actuators, they must be positioned to keep each other in check.
The hidden threat of involuntary interaction, with its potential for unitary strategic takeovers, is what is most dangerous. The more we decentralize intelligent systems of voluntary interactions, the better we will be at avoiding such a takeover. If a single entity grows sufficiently large that the rest of the world is not much bigger, the Schelling Point of voluntarism can be destroyed. In a world in which each entity is only a small part, voluntarism will be a general precedent that different players mutually expect in the attempt to pursue those goals.
Until a military perspective gets introduced into the AI narrative, the dynamic is better described as a concern to stay ahead in economic competition. In a world of voluntary cooperative interaction without a hidden threat of involuntary interaction, we can all benefit from creating improved AI services via the market because human beings would no longer be a bottleneck on productive activity.
From AI Value Alignment to Paretotropism
Let’s revisit the second threat; misaligned AI values. As long as future intelligences pursue their goals in a voluntary multipolar world, we need not worry about their goal structure. AI drives of acquiring more resources or seeking to stay alive are not problematic when they can only be achieved via voluntary cooperation. They become problematic when involuntary actions are possible. Can we do better than mere voluntary co-existence?
When two separately evolved sources of adaptive complexity come into contact, both may realize they can gain from their differences by cooperating to unlock the positive sum composition of their differing complexity. We certainly believe our lives are richer because of the richness of animals’ non-humanness. They are interesting by being a source of complexity. The atrocities committed against non-human animals is a result of the lack of voluntary architectures that frame interactions across species. Unlike non-human animals, we have a chance at putting voluntary boundaries in place with respect to future intelligences of our own making.
Civilization’s growth of knowledge and wealth results from human cooperation unlocking more knowledge in pursuit of more goals. What could we possibly hope to contribute to a human AI exchange? It might depend partly on who “we” are: will we be human, AI-assisted super-humans or human-AI symbiotes? Instead of focusing on weakening AI systems, a more robust long-term strategy might be to strengthen our own position in the game. Both, future AI technologies and the potential AI-induced bio and neurotechnology revolutions might help with that.
It is possible that AIs may eventually outcompete us on everything. But even if they are more advanced than us, they might still better serve their goals by cooperating with us if our complexity contributes at all to those goals. Even if you excel at everything, you can still benefit from specializing in one thing and trading with others who have a comparative advantage at different things. If we benefit from having deeper chains of specialists to cooperate with, the growth in adaptive complexity may well lead to continued cooperation.
We started this book with the observation that civilization is a superintelligence aligned with human interests. It’s getting rapidly more intelligent and its interactions steadily benefit without harming.8 By introducing artificial intelligences into this dynamic we may be able to further steepen our Paretotropian ascent.
Curious for more? Peter Norvig on A Modern Approach to AI.
Chapter Summary
In this chapter, we foreshadowed how an increasingly intelligent game could be increasingly beneficial for its players. The fear of an intelligent takeover by an AGI can be divided into the threat of first strike instabilities on the path and that of a successful takeover by an AGI singleton. The better we get at incorporating AI into our voluntary cooperative architecture in a multipolar manner, the better we can avoid both scenarios. Where will this future lead? Let’s find out in the final chapter.
Next up: ITERATE THE GAME | Racing Where?
What Do You Think about Machines That Think? by Eliezer Yudkowsky.
Basic AI Drives by Steve Omohundro.
For instance, Tom Bell worries that while DAOs may curtail default authoritarians’ power, their evolutions could create novel emergent pathologies. He is concerned that DAOs formed for malicious ends may come to exhibit locust swarm-like unstoppable behaviors. See Tom Bell’s Blockchain and Authoritarianism: The Evolution of Decentralized Autonomous Organizations, in Blockchain and Public Law: Global Challenges in the Era of Decentralization (not yet online).
See Engines of Creation by Eric Drexler.
Democracy in America by Alexis de Tocqueville.
Agreeing on contract terms can take weeks of back and forth with multiple rounds of offers and counter offers. If time is short, both parties can leave significant gains on the table. Wouldn’t it be nice to have an AI assistant that negotiates a contract template with both parties, presenting possible terms in the contract, such as payment time, cancellation, pricing, etc, to both parties who rate them. Based on the preference rankings, it suggests Pareto-preferred options such that one party can’t get a better deal without hurting the other. In addition to saving time, since the software can trade thousands of negotiating issues against each other in real-time, better deals may be achievable.
Importantly, while civilization has a tropism, it does not have a utility function. In fact, as we argued, civilization’s intelligence and safety both rest on its lack of a utility function, i.e., it is a negotiated compromise using an institutional framework that accommodates a great diversity of different ends.